导航
Introduction / Vertex Shaders, Hardware vertex shaders support
前言(Introduction)
纵观3D加速卡的发展历史,世界各大显卡制造公司的工程师们一直都在致力于增强3D芯片的功能,提高其运行速度。第一块3D加速卡只能够光栅化三角形,只支持最简单的几种色彩混合模式。剧烈的竞争导致了这个领域的科技得到了快速的发展。今天的3D加速卡已经学会了对三角形进行变换和光照处理,并且支持多重纹理混合,执行着色器程序(用于处理顶点和象素的小程序)等复杂操作。
Throughout the history of 3D-accelerators, engineers of the world's leading manufacturing companies increased the functionality of 3D-chips along with raising their speed. The first 3D-accelerators were only capable of rasterizing triangles and supported the simplest modes of color blending. Intense competition caused rapid development in this field of science. Today, 3D-accelerators have learned to transform and light triangles, perform complicated operations of blending several textures and execute shaders - short programs operating with vertices and pixels.
着色器技术已经在3D渲染程序中广泛使用了(比如Renderman),它象征着一种强大而灵活的面描绘方式。现在,这种技术正被引入3D加速卡。然而,我们也必须看到Renderman和OpenGL/DirectX所使用的着色器的不同之处。首先,我们应该知道Renderman所使用的着色器是用于进行相对较慢的渲染的,而后者纯粹就是针对实时渲染的。
The technology of shaders is widely used in 3D-rendering programs (like Renderman) and represents a powerful and flexible means of surfaces description. Today, this technology is being introduced into 3D-accelerators. However, in order to get the picture we have to see the difference between the Renderman shaders and those used in DirectX/OpenGL. First of all, we should remember that the former are meant for relatively slow rendering, while the latter are purely aimed at real-time rendering.
|
DirectX shader |
Renderman shader |
|
针对实时渲染
Aimed at real-time rendering |
针对相对比较慢速的渲染
Aimed at relatively slow rendering |
|
使用类汇编语言
Uses Assembler-like language |
使用类C语言
Uses C-like language |
|
程序简短,没有分支和循环,只能使用有限的寄存器,使用4D向量
Short shaders, no branching and loops, limited number of registers, works with 4D-vectors |
大量的句法性构造,包括循环和分支,着色器程序的长度没有限制,可使用的变量的数目也没有限制。使用矩阵。大范围的使用内建的功能函数。
A large number of syntactical constructions, including loops and branching, unlimited shader length and the number of available variables, works with matrices and has a wide range of built-in functions |
|
着色器种类:顶点着色器和象素着色器
Shader types: vertex and pixel |
着色器种类:表面,光源,置换,转换,体,图像
Shader types: surface, light source, displacement, transformation, volume, image |
在着色器出现之前,人们使用T&L(转换与光照)引擎来提供对顶点的几何处理,多重纹理(MT)引擎从属于光栅化过程。所有硬件上支持着色器的新显卡都同时支持T&L和多重纹理(MT)引擎,因此游戏开发者们在渲染的时候可以选择使用新方式或者老方式(有时也被称作可编程方式和固定函数方式)。
Before the shaders appeared, it was the T&L (transformation and lighting) engine that provided geometrical processing of vertices, while the multitexturing (MT) engine was in charge of rasterization. Vertex and pixel shaders have emerged as ideological successors to these engines. All new 3D-accelerators with hardware shaders support will also include the T&L and MT engines, thus allowing game developers to choose between the new and the old methods of rendering (also called programmable and fixed-function, respectively).
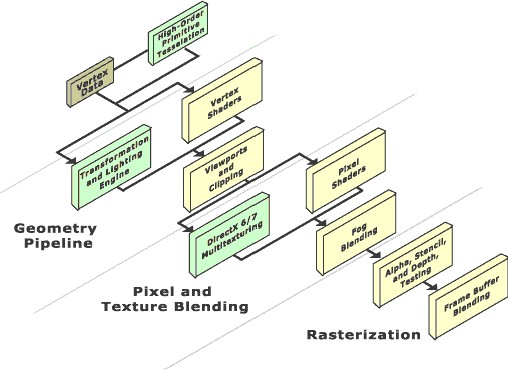
当着色器规范不断进化的时候,一系列版本的象素和顶点着色器被引入到DirectX中。本文主要是基于GeForce3所对应的着色器版本(顶点着色器v1.1,象素着色器v1.1)撰写的。
As the specification for shaders keeps evolving, tracking of versions of pixel and vertex shaders was introduced in DirectX. This article is mostly based on materials about GeForce3 which in terms of versions corresponds to Vertex Shader 1.1 and Pixel Shaders 1.1.
|
DirectX 8.0 |
DirectX 8.1 |
Vertex Shaders 1.0 (obsolete)
Vertex Shaders 1.1 |
|
Pixel Shaders 0.5 (obsolete)
Pixel Shaders 1.0 (obsolete)
Pixel Shaders 1.1 |
Pixel Shaders 1.2
Pixel Shaders 1.3
Pixel Shaders 1.4 |
顶点着色器(Vertex Shaders)
顶点着色器包含两个部分:着色器函数和着色器声明。着色器函数定义了单个顶点上可以执行的操作。从顶点数据流中读出顶点后,就由着色器函数来对其进行处理。顶点数据既可以由数据缓冲区提供,也可以由图元镶嵌引擎提供。原始数据(顶点坐标,法线,等等)将被载入到输入寄存器v0-v15中。一开始,输入寄存器的编号和其功能之间没有严格的对应关系,比如某个顶点的坐标既可以被载入v0,也可以被载入v15。事实上,不使用硬件镶嵌的时候,着色器根本就不知道输入寄存器中载入的是什么数据。为了让图像加速卡能够知道哪些输入寄存器应该载入哪些数据,就需要使用着色器声明。另外,为了尽可能高效的利用显存的带宽和AGP总线带宽,应该极力避免载入冗余数据。
A vertex shader consists of two parts: shader function and shader declaration. Shader function defines what operations must be executed on a single vertex. Vertices are read from the vertex data stream and are sequentially processed by the shader function. Data can be supplied either by the vertex buffer or by the primitive tessellation engine. Initial data (vertex coordinates, normal, etc.) are loaded into the input registers v0..v15. From the outset, the specification sets no strict correspondence between the register number and its function, for example a vertex coordinates can be loaded in either v0 or v15 registers. As a matter of fact, when no hardware tessellation is used, the shader is unaware of what data are loaded in the input registers. In order that the accelerator could know what data should be loaded in each input register, shader declaration is required. This is necessary to avoid loading redundant data and therefore to use the video memory bandwidth and that of the AGP bus as efficiently as possible.
着色器函数还可以处理一组临时寄存器r0-r7(读写方式),以及一组常量寄存器c0-c95(只读)。常量寄存器是用来存放着色器所需要的数据的,这些数据通过使用着色器声明来载入。每个寄存器允许存放一个四元矢量(每一元都是一个单精度实数)。着色器的输出结果是一个描述完整的顶点:x,y,z,w坐标,颜色,纹理坐标,雾强度和顶点大小。当然,并不是说着色器必须设置每一个输出寄存器(即,不必设置顶点的所有属性)。
Shader function also has at its disposal a set of temporary registers r0..r7 that can be read and changed, and a set of unchangeable constant registers c0..c95 in which the data required for the shader are loaded (also using the shader declaration). Each register allows storing a four-component vector (components are single-precision real numbers). The results of the shader's work is a fully described vertex: x,y,z,w-coordinates, colors, texture coordinates, fog intensity and point size. Of course, shader is not supposed to initialize every single output register.
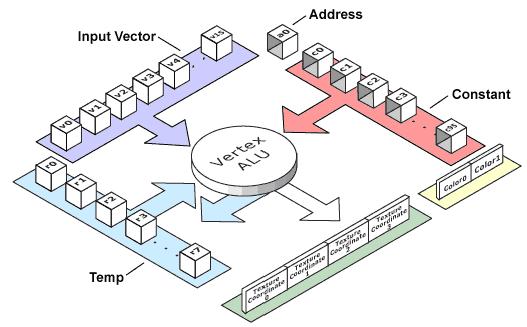
下表显示了顶点着色器可以使用的寄存器。请注意"端口数"这一列;他表示的是每条指令中,同一个寄存器可以被引用的最多次数。显然,端口数越多,顶点着色器执行的指令就越复杂。比如,在1.1版的着色器中,指令"add r0,v0,v0"无法使用,因为该指令包含了v0寄存器的两个引用,而v0寄存器的端口数只有1个。而指令"add r0,r0,r0"就是合法的,因为临时寄存器有三个端口。
The table below shows the registers available for the vertex shader. Please note the column "number of ports" - the maximal number of references to the same register inside a single instruction. It is understandable that the higher is the number of ports, the more complicated instructions can be executed in the vertex shader. For example, in the version 1.1 of the shader the instruction "add r0, v0, v0" will not work, for it contains two references to the register v0, while there is only one port available. On the other hand, the instruction "add r0, r0, r0" is valid, since three ports are available for the temporary registers.
|
寄存器
Register |
寄存器数量
Number of registers |
输入/输出
I/0 |
端口数
Ports |
描述
Description |
| an |
0 (1 in version 1.1) |
Write/Use |
1 |
Address register |
| cn |
96 |
Read |
1 |
Constant register |
| rn |
12 |
Read/Write |
3 |
Temporary register |
| vn |
16 |
Read |
1(2 in version 1.1) |
Input register |
着色器的硬件支持(Hardware vertex shaders support)
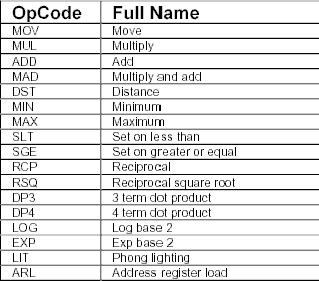
DirectX 8限制顶点着色器程序最大可以由128条指令组成。顶点着色器的命令集很小:只包含了17条指令,用于处理矢量和标量。程序员们必须在这个严格的限制下实现他们的想法。
The size of a vertex shader in DirectX 8 is limited to 128 instructions. The set of commands for vertex shaders is quite small - it contains as little as 17 instructions that work with vector and scalar quantities. Programmers have to implement their ideas within these strict limits.
现在,有两种3D加速卡已经从硬件上支持顶点着色器了,分别是GeForce3和Radeon(原文写的比较早,现在当然不止两种了^_^)。GeForce3能够以每个时钟周期一条指令的速度执行顶点着色器(只有两条指令运行时间超过一个周期:倒数RCP和平方根的倒数RSQ)。着色器程序越长,执行的就越慢,顶点处理的也就越慢。有三种方法可以提高速度:
Today, two 3D-accelerators have hardware support for vertex shaders, namely the GeForce3 and the Radeon. The GeForce3 is capable of executing a vertex shader at the speed of 1 instruction per clock cycle (only two instructions - RCP and RSQ - take more clock cycles). The longer is the shader, the slower it is executed, and therefore the lower is the vertex processing speed. There are three ways to increase the speed:
1.使用变量技巧来编写复杂的操作。例如,两个矢量的叉积仅仅使用两条指令就可以实现:MUL和MAD,不过矢量中元素的顺序改变了;
2.增加顶点流水线的条数。Radeon 8500和X-GPU(X-BOX使用的图形处理器)包含两条顶点流水线,因此能够以两倍的速度处理多边形;
3.超标量 - 并行处理多条没有相互影响的指令 - 正如CPU所做的那样。上面提到的X-GPU在单条顶点流水线中,每个时钟周期能够执行2-3条简单指令;
4.着色器高速缓存。为了提高加载速度,GeForce3允许同时在芯片上缓存多个着色器。DirectX并没有指定载入完毕的着色器被存储在什么地方,这是由驱动程序来完成的。使用OpenGL时,GeForce3程序的开发者就能够指定哪些着色器必须是"本地"的。
· To code complex operations using various tricks. For example, cross-product of two vectors is coded with only two instructions, MUL and MAD, but the sequence of vector components is changed:
MUL R1, R0.zxyw, R2.yzxw ;
MAD R1, R0.yzxw, R2.zxyw, -R1;
· To increase the number of vertex pipelines. The Radeon 8500 and the X-GPU (graphics processor to be used in the X-Box) will have two vertex pipelines that will double their polygon-processing speed.
· Superscalarity - paralleling several instructions that have no interconnections among them (just as in the CPU). The abovementioned X-GPU can execute 2-3 simple instructions per clock cycle in one vertex pipeline.
· Shaders caching. The GeForce3 allows caching several shaders on the chip at once in order to load them faster. DirectX provides no implicit assignment of where to store the ready shaders, it is the driver that controls the shaders caching. With OpenGL the developers of the GF3 drivers made it possible to indicate which shaders must be "resident".